AI芯片到底指什么?一句话:专为人工智能算法设计的处理器,能在更低功耗下完成更高密度的矩阵运算。
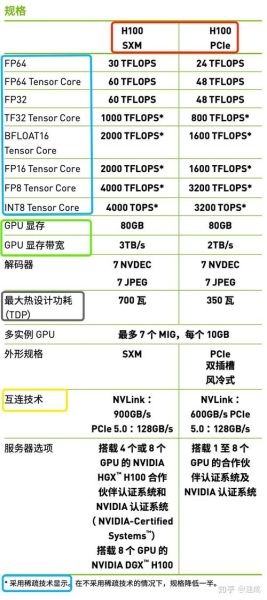
AI芯片与传统芯片的三大差异
并行计算架构:CPU串行处理,AI芯片采用SIMD或脉动阵列,一次可并行上千次乘加运算。
数据流优化:传统芯片把数据搬来搬去,AI芯片把计算单元“贴”在数据旁边,减少80%以 *** 存延迟。
精度可配置:支持FP16、INT8甚至INT4,精度按需切换,算力瞬间翻倍。
如何衡量AI芯片的真实性能?
TOPS只是起点,能效比才是关键
很多厂商标称100 TOPS,却避谈每瓦性能。实际部署时,25 TOPS@5 W的芯片往往比100 TOPS@30 W更受欢迎。
延迟与吞吐的平衡
自动驾驶场景要求端到端延迟≤10 ms,而云端训练更关注吞吐。芯片设计必须针对场景做取舍。
提升AI芯片性能的六大技术路线
1. 制程微缩:从28 nm到3 nm,晶体管密度提升近十倍,动态功耗下降40%。
2. 存算一体:把SRAM或RRAM嵌入计算单元,消除冯·诺依曼瓶颈,能效提升10~100倍。
3. 稀疏化计算:跳过权重为零的运算,ResNet-50推理速度提升1.9倍,功耗下降35%。
4. 片上 *** NoC优化:采用2D Torus或Mesh拓扑,核心间延迟从200 ns降至50 ns。
5. 混合精度训练:前向FP16、反向FP32,配合Loss Scaling,模型收敛速度与FP32持平,显存占用减半。

6. 专用指令集:针对Transformer设计Flash-Attention指令,矩阵乘法延迟降低62%。
自研还是外购?落地决策指南
自研芯片的门槛有多高
一次性流片费用:7 nm约3000万美元,5 nm接近5000万美元。团队规模至少200人,周期18~24个月。
外购方案的隐藏成本
英伟达A100单价1万美元,但整机功耗10 kW,数据中心PUE若从1.3优化到1.1,五年电费可省200万美元。
边缘场景下的性能优化实战
以智能摄像头为例,需求是1080p@30 fps实时检测。
- 模型:YOLOv5-nano剪枝后仅1.2 MB
- 芯片:4 nm工艺,INT8算力8 TOPS@2 W
- 优化:采用Channel-wise蒸馏,mAP仅下降0.7%
最终整机功耗3.8 W,比上一代方案降低55%。
未来三年值得关注的三大趋势
Chiplet异构集成:把CPU、GPU、NPU通过先进封装拼在一起,良率提升20%,成本下降15%。
光电计算:硅光芯片在1 ns内完成8×8矩阵乘法,功耗仅为电子方案的1/50。
自适应编译器:根据实时负载动态重排算子,ResNet-50在不同batch size下保持95%以上利用率。
常见疑问快答
Q:7 nm和5 nm差距大吗?
A:同架构下,5 nm性能提升15%,功耗下降25%,但流片成本增加60%,需按出货量权衡。
Q:INT4精度会不会导致模型崩掉?
A:对分类任务影响<1%,但对超分或生成模型PSNR可能下降3 dB,需逐层做量化感知训练。
Q:开源NPU IP靠谱吗?
A:Verilog代码可用,但缺少DFT、物理实现、软件栈,完整商用至少补30人年工作量。
评论列表